Tokens, training, context windows, hallucinations. How language models actually process your questions and generate answers. No PhD required.
A Large Language Model (LLM) is software that has learned the statistical patterns of language by reading billions of pages of text. It does not understand your question the way a person does. It predicts what text is most likely to come next, based on everything it has seen before. Think of it as the world's most sophisticated autocomplete. When you type a message in your phone and it suggests the next word, that is the same principle, scaled up by a factor of several billion.
The 'Large' in LLM refers to the number of parameters: the internal dials the model uses to make predictions. GPT-4 has an estimated 1.8 trillion parameters. Claude, Gemini, and Llama have hundreds of billions each. More parameters generally means the model can capture more nuanced patterns, but it also means more compute, more cost, and more energy.
An LLM does not look up answers in a database. It generates them word by word based on probability. This is both its strength (it can be creative, flexible, conversational) and its weakness (it can be confidently wrong).
LLMs do not read words the way you do. They split text into tokens: chunks that can be whole words, parts of words, or even single characters. Common words like 'the' or 'and' are one token. Longer or rarer words get split into pieces. The word 'understanding' becomes two or three tokens depending on the model.
The sentence "AI is transforming logistics" splits into:
Blue = full word tokens. Purple = sub-word tokens. 4 words became 6 tokens.
On average, one English word equals roughly 1.3 tokens. A page of text (about 750 words) is around 1,000 tokens. This matters because everything in the AI world is priced and measured in tokens: how much text you can send, how long a reply you get, and what it costs. When a model says it has a '200K context window,' that means roughly 150,000 words.
Non-English languages are typically less token-efficient. A Dutch sentence often costs 20-40% more tokens than the English equivalent, because tokenizers were primarily trained on English text. This means higher costs and faster context exhaustion when working in Dutch.
Building an LLM happens in two major phases. Understanding these explains a lot of the behavior you see when you use one.
Pre-training is the expensive part: it takes months on thousands of specialized GPUs and costs tens of millions of dollars. This is where the model absorbs its 'knowledge.' But a pre-trained model is not yet useful. It can finish sentences, but it does not know how to have a conversation or follow instructions.
Fine-tuning teaches the model to be an assistant. Techniques like RLHF (Reinforcement Learning from Human Feedback) train the model to prefer helpful, harmless, and honest responses. This is why ChatGPT can chat with you, while the raw GPT-4 base model would just continue whatever text you started.
Because training data is collected at a fixed point in time, every model has a knowledge cutoff date. Events after that date are unknown to the model unless it can search the web. This is why AI sometimes gives outdated answers, and why web-connected AI assistants are more reliable for current information.
The context window is the total amount of text an LLM can hold in its 'working memory' during a single conversation. Everything you send and everything it replies with counts toward this limit. Once the window is full, the model starts losing the beginning of the conversation.
Here is the catch: advertised context sizes are not the full story. Research consistently shows that model performance degrades as the context fills up. A model with a 200K token window typically becomes unreliable around 130K tokens. Think of it like a desk: it might be 2 meters long, but the part you can actually work on is smaller.
For long conversations, start fresh sessions instead of extending one thread forever. The model performs best when the context is not saturated. If you paste a long document, keep your instructions concise to leave room for the model to think.
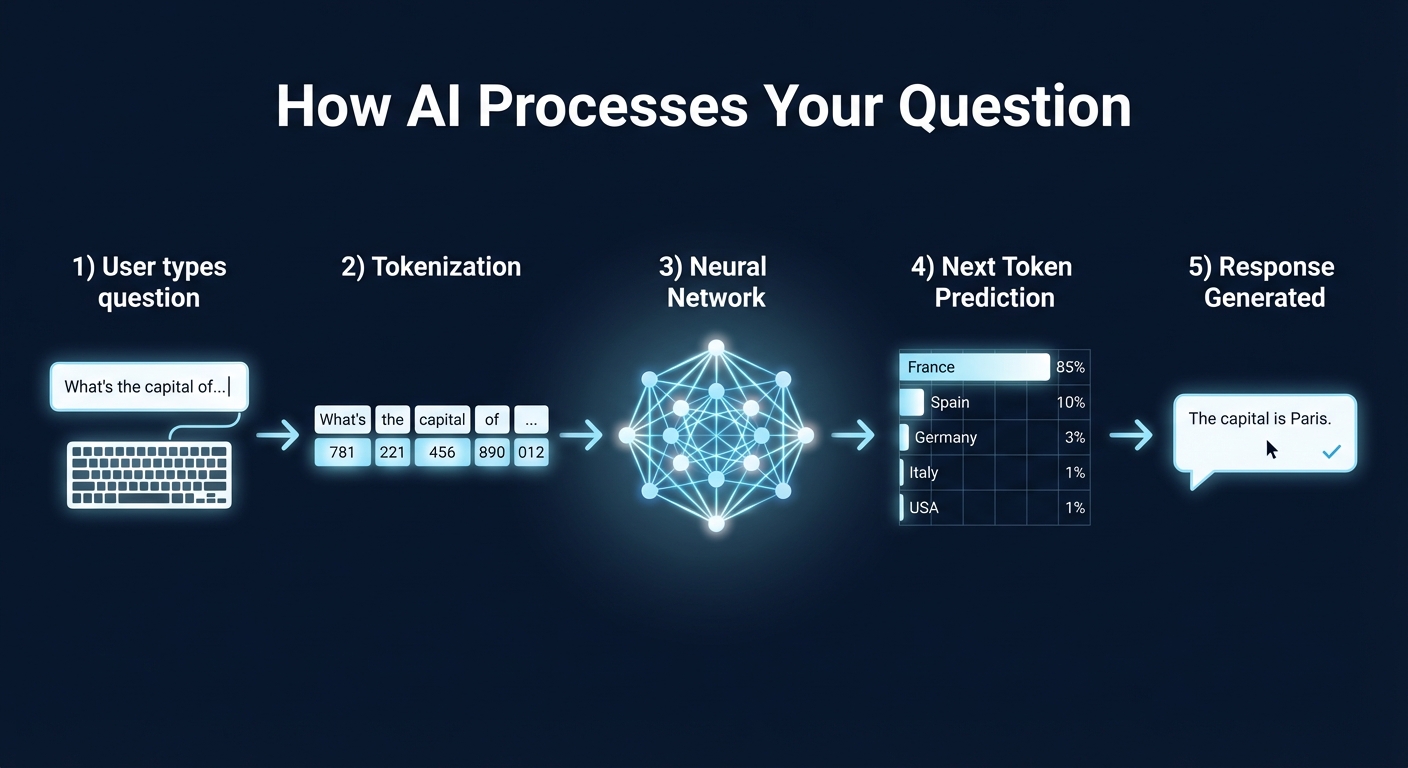
When you send a prompt, the model does not read your message and then compose a reply the way a person would. It processes your entire input at once, then generates the response one token at a time. For each token, it calculates probability scores for every possible next token in its vocabulary (typically 50,000 to 200,000 options) and picks one.
This is why you see AI responses appear word by word in the chat, as if it is typing. It actually is generating each piece in sequence. It is also why the model cannot 'go back and fix' something mid-sentence without special prompting. Each token is committed the moment it is generated.
Temperature is a setting that controls how the model picks from its probability scores. Low temperature (close to 0) means it almost always picks the highest-probability token, making output predictable and factual. High temperature (close to 1 or above) means it explores lower-probability options, making output more creative and varied, but also more prone to errors.
Most AI chatbots default to 0.7 -- a balance between coherence and flexibility
Because LLMs generate text based on probability rather than looking up facts, they sometimes produce information that sounds plausible but is simply false. The AI community calls this 'hallucination.' It is arguably the biggest practical challenge of using LLMs today.
Hallucination rates vary widely between models. The best performing models in early 2026 achieve rates below 1% on standardized benchmarks, while less capable models hallucinate in up to 30% of responses. In specialized domains like medicine or law, even well-performing models can fabricate references in a significant portion of their outputs.
Stating statistics, dates, or claims that do not exist. The model is pattern-matching, not fact-checking.
Inventing book titles, URLs, research papers, or author names that look real but do not exist.
Presenting wrong information with the same confident tone as correct information. No hesitation, no caveats.
Be suspicious of very specific claims (exact percentages, specific dates, named sources) in domains where you cannot verify. Ask the model for its sources. Cross-check critical facts with a web search. If the model says 'a study found that...' without naming the study, assume it may be fabricated until you verify it yourself.
Understanding how LLMs work under the hood directly improves how you use them. Here are the practical takeaways.
Be specific, not vague. Since the model predicts the next most likely token, vague prompts lead to generic responses. The more context and specifics you provide, the more the probability distribution shifts toward useful output. 'Write me a marketing email' produces average text. 'Write a marketing email for a logistics company launching a route optimization tool, targeting operations managers, tone: professional but not stiff' produces something you can actually use.
Think about token budget. Every word you send eats into the context window. Do not paste your entire document if you only have a question about one paragraph. Be concise in your instructions, but thorough in your context. This is not a contradiction: it means cutting filler while keeping the information the model needs to do its job.
Verify, do not trust. Knowing that LLMs generate text probabilistically, not factually, should permanently change your relationship with AI output. Use it as a first draft, a starting point, a thinking partner. Never use it as a source of truth without checking. The people who get the most value from AI are the ones who treat it as a capable but fallible collaborator.
Structure helps. LLMs respond well to structure in prompts because structured text has clear patterns. Use numbered lists for multi-step instructions. Use headers to separate sections. Tell the model what format you want the output in. The clearer the pattern you establish, the better the model continues it.